Computer Science
Sanal Belleğin Temelleri: İşletim Sistemlerinin Hafıza Yönetimi Sanatı
December 23, 2025
Bilgisayar mimarisinde, verinin nerede saklandığı ve işlemciye (CPU) ne hızla ulaştığı performansın en kritik belirleyicisidir. Disk depolama alanları kalıcıdır ancak yavaştır. Ana bellek (RAM) ise uçucudur (elektrik kesilince veri kaybolur) ancak diske göre çok daha hızlıdır. Peki, CPU’nun zaten kendi içinde çok hızlı “yazmaçları” varken neden ana belleğe ihtiyaç duyarız? Cevap kapasitededir. Yazmaçlar sınırlı sayıdadır ve büyüklükleri azdır; binlerce değişkeni veya büyük veri yapılarını tutamazlar. Bu yüzden CPU, daha karmaşık ve büyük verileri işleyebilmek için ana belleği bir “sahne” olarak kullanır.
Kernel kaynak kodunu ilk okuduğumda, do_page_fault() fonksiyonunun 500 satır olduğunu görünce şok olmuştum. “Alt tarafı bir bellek hatası, ne kadar karmaşık olabilir ki?” demiştim. Meğer o zamanlar buzdağının sadece görünen kısmıyla oynuyormuşum…
Ancak modern işletim sistemlerinde programlar doğrudan fiziksel RAM adreslerini kullanmazlar. Bunun yerine “Sanal Bellek” adı verilen kapsamlı bir soyutlama katmanı devreye girer. Bu yazıda, basit bellek atamasından modern “Sayfalama” tekniklerine, “Yığın” ve “Öbek” yönetiminin donanım seviyesindeki detaylarına kadar iniyoruz.
1. İlk İlkel Yöntemler ve “Dış Parçalanma” Sorunu
Sanal belleğin neden bu kadar karmaşık olduğunu anlamak için, önce en basit yaklaşımı inceleyelim: Bitişik bellek ataması.
Bu yöntemde işletim sistemi, her programa (sürece) bellekte tek parça, kesintisiz bir blok ayırır. Bir program başladığında sistem boş alanlara bakar ve programa yetecek büyüklükte bir bölgeyi ona verir. Boşluğu bulmak için kullanılan birkaç klasik algoritma vardır:
- First-fit (İlk uygun): Yeterince büyük ilk boşluğu bulur ve kullanır. En hızlısıdır, çünkü belleği baştan taramaya başlar ve ilk fırsatta durur.
- Best-fit (En iyi uygun): Tüm boşlukları inceler ve programa tam kıyasla en az fazlayı bırakacak, yani en küçük uygun boşluğu seçer.
- Worst-fit (En kötü uygun): Tam tersi, en büyük boşluğu verir. Mantığı, geriye daha kullanışlı parçalar kalacağıdır.
Kulağa basit ve mantıklı geliyor, değil mi? Ama zamanla büyük bir sorun ortaya çıkıyor: Dış parçalanma
Programlar belleğe girip çıktıkça, boş alanlar küçük küçük parçalara bölünüyor. Toplamda yeterince boş yer olsa bile, bu boşluklar dağınık ve hiçbirisi yeni bir programa yetecek kadar büyük olmayabiliyor. Örneğin, iki dolu blok arasında kalan küçük boşluklar tamamen kullanılamaz hale geliyor. En kötü durumda bellek “delik deşik” oluyor ve yeni program başlatamıyorsunuz.
Bir başka sıkıntı da, bir programın çalışma sırasında ne kadar belleğe ihtiyaç duyacağını önceden tam olarak bilememek. Eğer ayrılan alan yetmezse, programı durdurup daha büyük bir bitişik bloğa taşımak gerekiyor ki bu hem yavaş hem de zahmetli.
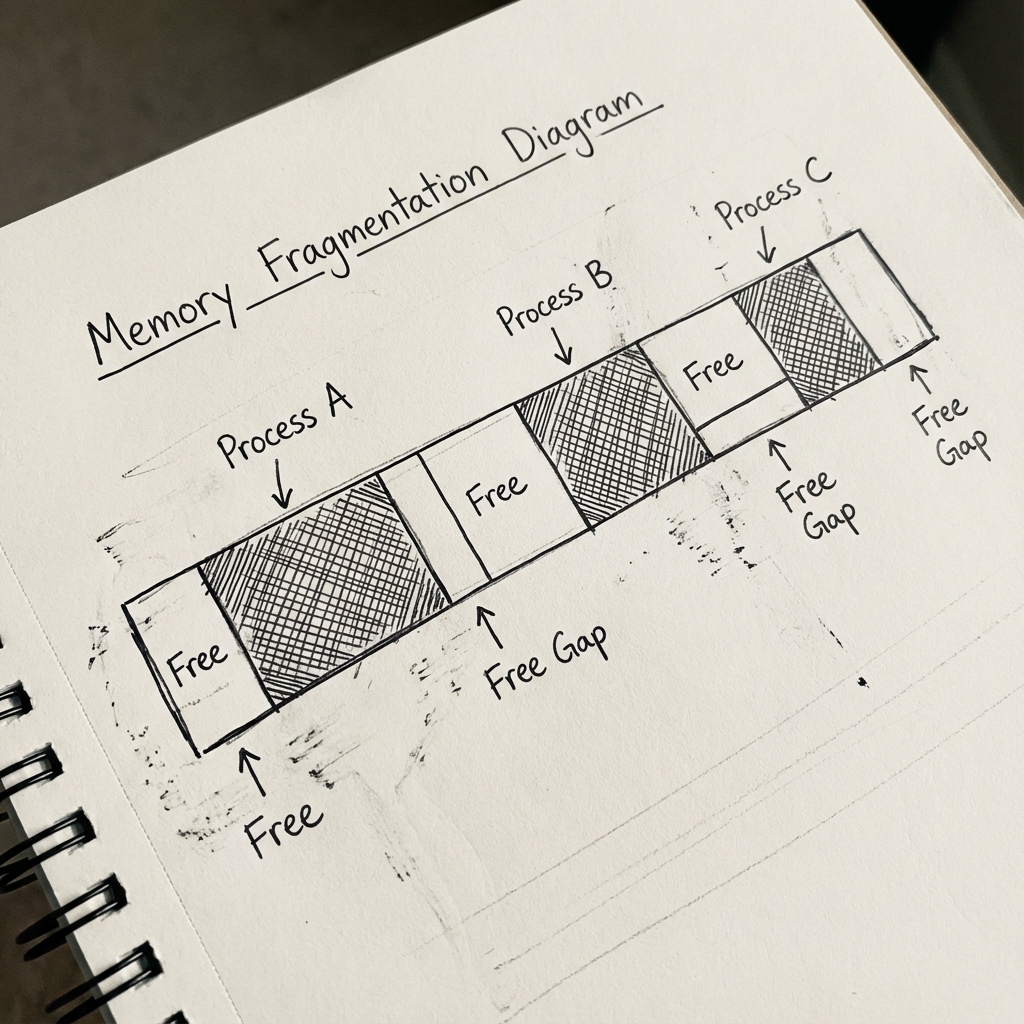 Şekil 1: Dış parçalanma (External Fragmentation) sorunu. Bellekte toplamda yeterli boş yer olsa bile, bu boşluklar (Free Gap) dağınık olduğundan büyük bir süreç tek parça halinde yüklenemez.
Şekil 1: Dış parçalanma (External Fragmentation) sorunu. Bellekte toplamda yeterli boş yer olsa bile, bu boşluklar (Free Gap) dağınık olduğundan büyük bir süreç tek parça halinde yüklenemez.
2. Modern Çözüm: Bellek Sayfalama (Paging)
İşletim sistemleri bu parçalanma sorununu çözmek için çok daha akıllı bir yöntem geliştiriyor: Sayfalama
Burada fiziksel RAM, sabit boyutlu küçük bloklara, bunlara çerçeve diyoruz, bölünüyor. Sanal bellek ise aynı boyutta sayfa adlı bloklara ayrılıyor (genelde 4 KB boyutunda).
En güzel yanı şu: Bir programın sayfaları fiziksel bellekte yan yana olmak zorunda değil! İşletim sistemi, programın sanal sayfalarını RAM’deki boş çerçevelere rastgele yerleştirebiliyor. Ama programa göre her şey hala tek parça, bitişik bir bellek gibi görünüyor.
Adres Çevirisi Nasıl Çalışıyor?
Bir program sanal bir adrese erişmek istediğinde, bu adres donanım desteğiyle fiziksel adrese çevriliyor. Süreç kabaca şöyle:
- Sanal adresin parçalanması: Adres iki kısma ayrılır: üst bitler sayfa numarası (p), alt bitler ofset (d). Ofset, sayfanın içindeki bayt konumunu gösterir.
- Sayfa tablosuna bakma: Her programın kendine özel bir sayfa tablosu vardır. Bu tabloda, her sanal sayfa numarası (p) karşılık geldiği fiziksel çerçeve numarası (f) ile eşleştirilmiştir.
- Çeviri: Donanım (MMU), tablodan fiziksel çerçeve numarasını alır, sanal adresin sayfa kısmını bununla değiştirir. Ofset kısmı ise aynen kalır. Sonuç: Fiziksel adres!
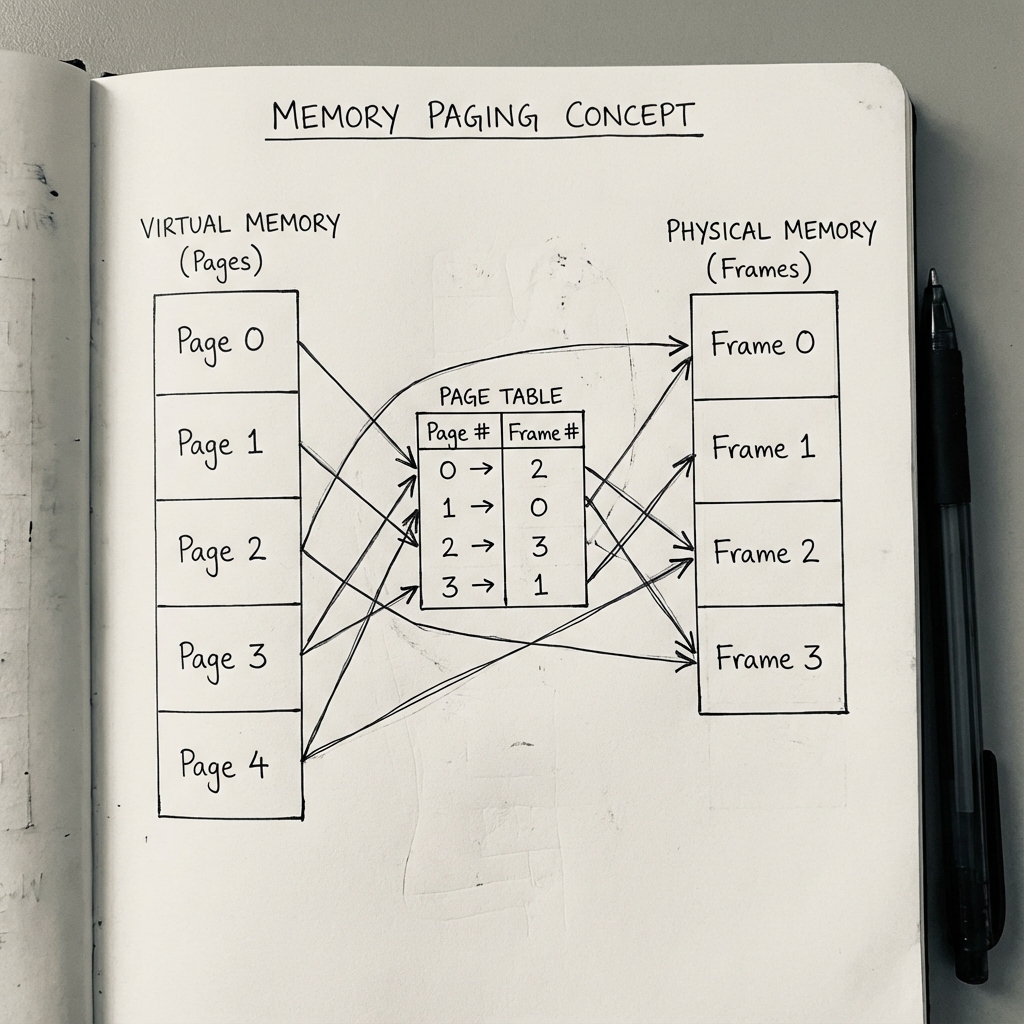 Şekil 2: Bellek Sayfalama mekanizması. Sanal bellekteki bitişik sayfaların, sayfa tablosu aracılığıyla fiziksel RAM’deki rastgele çerçevelere dağıtılması.
Şekil 2: Bellek Sayfalama mekanizması. Sanal bellekteki bitişik sayfaların, sayfa tablosu aracılığıyla fiziksel RAM’deki rastgele çerçevelere dağıtılması.
Bu tablolalar basit sistemlerde tek seviye olabiliyor, ama modern işletim sistemlerinde (Linux, Windows) yer tasarrufu için çok seviyeli sayfa tabloları kullanılıyor. Ayrıca daha gelişmiş yapılar da var: Örneğin, hash tabanlı eşlemeler ya da tersine çevrilmiş tablolar, ki bunlar fiziksel çerçeveyi anahtar olarak tutup hangi sanal sayfanın ona ait olduğunu gösteriyor.
Bu mekanizma sayesinde önemli avantajlar elde ediyoruz. Mesela Google Chrome’da her sekme ayrı bir süreç olsa bile, libc gibi ortak kütüphaneler fiziksel bellekte sadece bir kez yükleniyor. Her sekmenin sayfa tablosu bu kütüphanenin sayfalarını aynı fiziksel çerçevelere işaret ediyor. Böylece bellekte ciddi oranda yer tasarrufu sağlanıyor.
3. Talep Üzerine Sayfalama (Demand Paging) ve Sayfa Hataları
Büyük bir programı çalıştırmak için tamamını birden RAM’e yüklemek zorunda değiliz. Örneğin, devasa bir açık dünya oyununda oyuncunun şu anda bulunduğu bölgeye ait veriler bellekte olsun, geri kalan kısım diskte beklesin; oyuncu ilerledikçe gereken parçalar yüklenir. İşte bu mantığa talep üzerine sayfalama diyoruz.
Bir program çalışırken sayfalarının bir kısmı fiziksel RAM’de bulunur, bir kısmı ise diskteki takas alanında bekler. Sayfa tablosunda her sayfa için bir geçerli-geçersiz biti vardır: “Geçerli” ise sayfa RAM’de, “Geçersiz” ise ya diskte ya da o adres hiç sürece ait değil demektir.
Program, RAM’de olmayan bir sayfaya erişmeye kalkarsa sayfa hatası meydana gelir. İlk defa page fault handling’i debugger’da step-by-step takip ettiğimde, “Vay be, kernel bu kadar iş yapıyor ama biz farkında bile değiliz” demiştim. Bu bir hata değil, normal bir durumdur ve işletim sistemi şu adımları izler:
- Erişilen adresin gerçekten sürecin mantıksal adres alanında olup olmadığını kontrol eder (değilse süreci öldürür).
- Adres geçerliyse ama sayfa bellekte değilse, boş bir fiziksel çerçeve bulur (yoksa başka bir sayfayı diske çıkarır).
- Diskten ilgili sayfayı okuyup bu çerçeveye yükler.
- Sayfa tablosunu günceller, biti “geçerli” yapar.
- Programı tam kaldığı yerden devam ettirir.
Bu mekanizma sayesinde programlar fiziksel RAM’den çok daha büyük sanal bellek kullanabilir. Linux’ta top veya ps komutlarıyla bir sürecin bellek kullanımına baktığınızda iki önemli değer görürsünüz:
- RSS (Resident Set Size): Sürecin şu anda fiziksel RAM’de gerçekten kapladığı alan (paylaşılan kütüphaneler dahil).
- VSZ (Virtual Size): Sürece ayrılmış toplam sanal bellek miktarı. Buna diskte bekleyen sayfalar, swap alanı ve henüz dokunulmamış (malloc edilmiş ama kullanılmamış) bölgeler de dahildir.
Bir keresinde memory leak yaşayan bir PHP uygulamasını debuglarken, pmap ile process’in memory map’ine baktığımda heap’in 4GB’a ulaştığını görmüştüm. Kodda basit bir döngü hatası, sunucuyu yavaşça boğuyordu.
4. Sanal Bellek Düzeni: Bir Sürecin Anatomisi
Linux’ta (x86-64 mimarisinde) bir sürecin sanal adres alanı aşağıdan yukarıya doğru belirli bölümlere ayrılır. Tipik düzen şöyle görünür:
- Metin Segmenti: Programın makine kodlarını içerir. Genellikle salt-okunur olduğundan paylaşılan kütüphanelerle ortak kullanılır.
- Veri Segmentleri (.data ve .bss): İlklendirilmiş global/statik değişkenler (.data) ve sıfırlanmış/ilklendirilmemiş olanlar (.bss) burada yer alır.
- Öbek: Dinamik bellek tahsisleri (malloc, new vb.) için kullanılır ve yukarı doğru büyür.
- Bellek Eşlemeli Bölgeler: Paylaşılan kütüphaneler, mmap ile açılan dosyalar gibi özel eşlemeler buradadır.
- Yığın: Fonksiyon çağrıları ve yerel değişkenler için kullanılır, aşağı doğru büyür.
- Kernel Alanı: En üstte yer alır ve kullanıcı modu süreçleri buraya doğrudan erişemez (kernel modu gerektiğinde geçiş yapar).
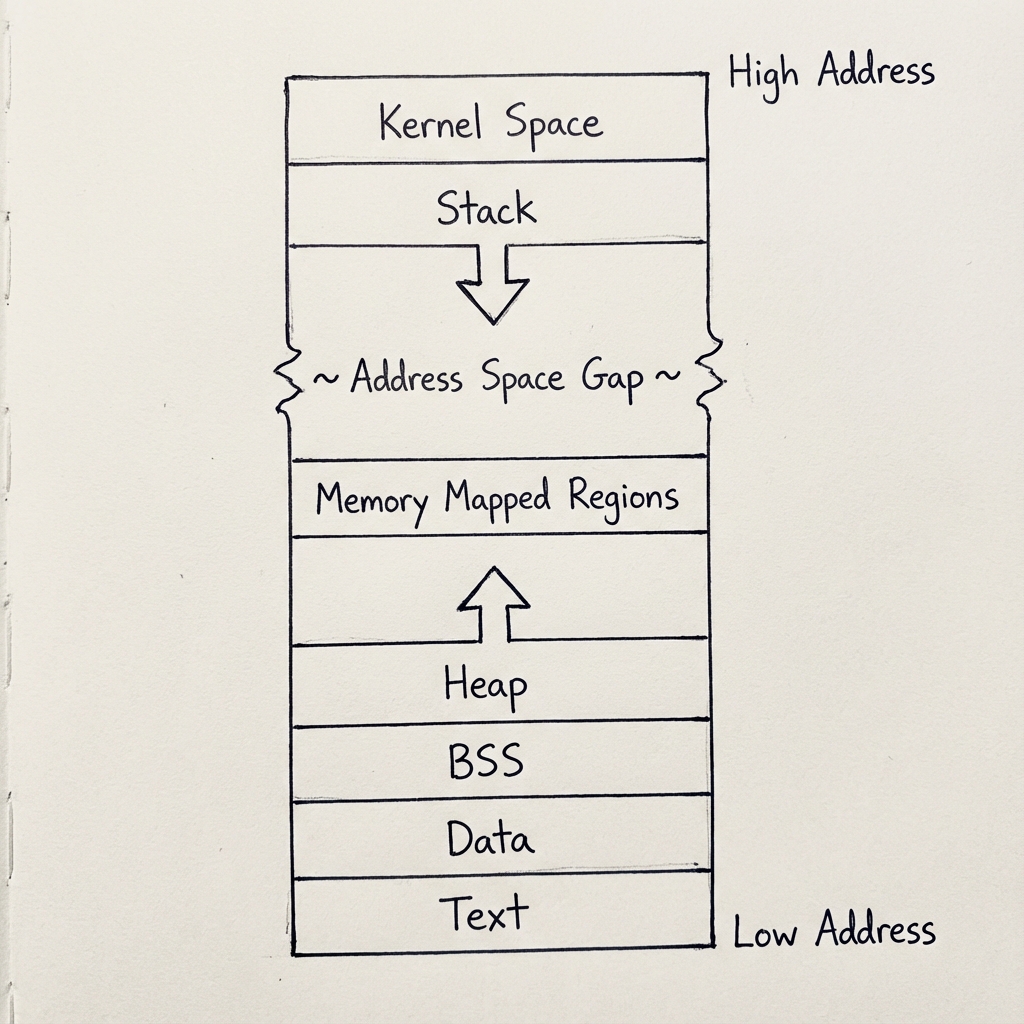 Şekil 3: Linux’ta bir sürecin sanal bellek yerleşimi. Yığın yukarıdan aşağıya, Öbek ise aşağıdan yukarıya doğru büyür. Aradaki boşluk, dinamik büyüme için esneklik sağlar.
Şekil 3: Linux’ta bir sürecin sanal bellek yerleşimi. Yığın yukarıdan aşağıya, Öbek ise aşağıdan yukarıya doğru büyür. Aradaki boşluk, dinamik büyüme için esneklik sağlar.
Yığın ile öbek arasında genellikle büyük bir boşluk bırakılır; ikisi büyüdükçe birbirine yaklaşır ama çarpışmamaları için guard page’ler konulur.
4.1. Yığın Mimarisi ve Neden Bu Kadar Hızlı?
Yığın, LIFO prensibiyle çalışır ve adres alanı aşağı doğru büyür. Bir fonksiyon çağrıldığında onun için bir yığın çerçevesi oluşturulur. Bu çerçeve şu bilgileri içerir:
- Yerel değişkenler
- Fonksiyon parametreleri
- Geri dönüş adresi
- Önceki çerçeve işaretçisi
Yığının bu kadar hızlı olmasının sebepleri:
- CPU, yığının tepesini takip etmek için özel bir yazmaç tutar: x86-64’te RSP. Bellek ayırmak için sadece RSP’yi birkaç bayt azaltmak yeter; bu tek bir CPU talimatıyla yapılır. Üniversitedeyken Stack pointer’ı anlamak için haftalar harcadım. Saç baş yolarken bir anda jeton düştü: Sadece “aşağı gidiyor”! :) O karmaşık görünen yapı aslında sadece basit bir çıkarma işlemiymiş.
- Değişkenlerin boyutu ve konumları derleme zamanında bellidir, runtime’da hesap yapmaya gerek yok.
- İşletim sistemine sistem çağrısı yapmadan bellek tahsis edilebilir.
Ayrıca her ipliğin kendine ait ayrı bir yığını vardır (genellikle 2-8 MB). Bu sayede iplikler yığın üzerinde tamamen bağımsız çalışır, kilit gerekmez ve performans çok yüksektir.
4.2. Öbek Yönetimi ve Neden Daha Yavaş?
Öbek, yığının aksine yukarı doğru büyür ve dinamik bellek tahsisleri için kullanılır. Öbeğin üst sınırına program break (brk) denir; bu sınırın ötesi henüz sürece ait değildir.
Programcılar genelde malloc, free, new, delete gibi fonksiyonları kullanır. Bu fonksiyonlar aslında altta şu işleri yapar:
- malloc: Önce daha önce free ile serbest bırakılmış blokların listesini tarar. Uygun boyutta bir blok bulursa (first-fit, best-fit gibi stratejilerle) onu verir. Blok büyükse ikiye böler: Bir kısmını kullanıcıya, kalanını listeye geri koyar.
- Eğer listede uygun blok yoksa, kernelden yeni alan istenir: Eskiden
brk/sbrksistem çağrılarıyla program break yukarı taşınırdı. Günümüzde çoğu sistemdemmapile anonim eşlemeler tercih edilir (daha esnek olduğu için).
Heap’in dezavantajları:
- Tüm iplikler aynı öbeği paylaşır. Çok iplikli bir programda
malloc/freeçağrıları sırasında veri yapılarının bozulmaması için mutex (kilit) kullanılır. Bu kilitlenme heap tahsisini yığına göre çok daha yavaş hale getirir; bazen onlarca kat yavaş olabilir. - Parçalanma riski vardır (iç ve dış parçalanma).
- Tahsis ve serbest bırakma işlemleri daha karmaşıktır; sürekli birleştirme ve liste yönetimi gerekir.
Kısacası, mümkün olduğunca yığın kullanın; dinamik ve öngörülemeyen tahsisler gerektiğinde öbeğe başvurun. Modern dillerde akıllı pointer’lar ve arena allocator’lar gibi tekniklerle heap’in dezavantajlarını azaltmaya çalışıyoruz.
5. Bellek Eşleme (mmap)
Yığın ve öbek dışında, modern işletim sistemlerinin en temel araçlarından biri bellek eşleme, yani mmap sistem çağrısıdır. Bu mekanizma, belleği yönetmenin çok daha esnek ve verimli bir yolunu sunar.
Temelde iki türü vardır:
- Dosya eşleme: Bir dosyayı doğrudan sanal bellek adresine bağlarsınız. Artık dosyayı read/write ile uğraşmadan, sıradan bir dizi veya yapı gibi bellek üzerinden okuyup yazabilirsiniz. Dosya değişince bellekteki görüntü de değişir. Bu, büyük dosyaları işlerken büyük hız kazandırır; örneğin veritabanları veya video düzenleme programları sıkça kullanır.
- Anonim eşleme: Hiçbir dosyaya bağlı olmayan, sıfırlarla dolu (ya da belirsiz içerikli) bir bellek bölgesi yaratır. Aslında büyük malloc çağrıları arka planda genellikle bunu kullanır:
libc, belirli bir boyuttan sonrabrk/sbrkyerinemmapile anonim eşleme yapmayı tercih eder çünkü daha esnek ve güvenli.
Eşlemeler özel veya paylaşılan olabilir:
- Paylaşılan: Birden fazla süreç aynı fiziksel sayfaları görür. Bir süreç yazarsa diğerleri de değişikliği hemen görür. Bu, süreçler arası iletişim (IPC) için etkili bir yöntemdir.
- Özel: En çok kullanılanı budur ve burada Yazma Anında Kopyala (COW) devreye girer. Eşleme yapıldığında tüm süreçler aynı fiziksel sayfaları paylaşır (bellek tasarrufu!). Ama bir süreç o sayfaya yazmaya kalkarsa, kernel hemen o sayfanın bir kopyasını oluşturur ve değişikliği sadece o sürece özel yapar. Diğer süreçler eski hali görmeye devam eder.
Bu COW tekniği sayesinde fork() sonrası çocuk süreçler ebeveynle aynı belleği paylaşır gibi görünür ama aslında yazma oldukçada kopyalanır; hem hızlı hem de belleği boşa harcamaz.
Go, Rust gibi modern diller kendi bellek yöneticilerini yazarken sıkça doğrudan mmap kullanır. Örneğin Go’nun runtime’ı, garbage collector’ın ihtiyaç duyduğu büyük hafıza havuzlarını anonim eşlemelerle oluşturur. Bu sayede heap yönetimini kendi stratejilerine göre optimize edebilirler.
Sonuç
Bir sonraki yazıda bu teorik bilgiyi pratiğe dökeceğiz:
- Basit bir C programı ile kendi page fault’umuzu tetikleyeceğiz.
straceile kernel’in arka planda ne yaptığını gözlemleyeceğiz.- Stack overflow kasıtlı olarak yaratıp ASAN’ın nasıl yakaladığını göreceğiz.
Takipte kalın, belleği çökertmeye başlıyoruz!
Yorumlar